Building a Scalable Architecture for a Real-Time Collaborative Video Editor


Turn your texts, PPTs, PDFs or URLs to video - in minutes.

On February 29, 2024, we launched a new feature—a real-time collaborative video editor—that tested our technical skills, planning skills, and ability to articulate what a feature really needed to be viable.
A feature like this demands a high bar for even minimum viability. If it didn’t reliably scale, users would struggle to work together, making a potentially exciting new feature dead on arrival.
We learned a lot, and in this post, we want to cover the journey from business case to implementation and from rollout to results.
Why we needed a collaborative editor
At Synthesia, we provide an AI video platform where users can create professional-looking videos with synthetic avatars.
Our primary customers come from learning and development, where users create training courses, how-to articles, and other educational materials.
These materials are often critical to our users but frequently require updates. In traditional video production, we're used to making a tradeoff between the quality of the video we produce and the ability to iterate on the content. Users turn to Synthesia because they can have their cake and eat it too by creating better content more cheaply while easily iterating on that content over time.
The criticality of the materials often means that our users want multiple people in the room to work together to figure out how a new module should look, feel, and sound. With real-time collaboration, we can allow multiple people to use the editor at once and create a Google Docs- or Figma-esque experience for video editing.
This isn’t just a neat or nice-to-have feature for us. With a collaborative editor, we can:
- Grow when one user invites their colleagues to work with them, turning those colleagues into Synthesia users.
- Differentiate from video editors that can’t do this and, at the same time, reach “parity” with tools like Google Docs, which have led users to expect collaboration as a default.
- Tighten the feedback loop by enabling our customers to request feedback on materials in progress with their stakeholders rather than reshooting videos with actors
Initially, we had a proof of concept working in a development environment, but it was far from ready for production.
At the time, we only had one server to support real-time collaboration, and we quickly realized that scalability would be the primary challenge in making this production-ready.
From the get-go, we knew users would have to be connected to the same server, meaning the servers had to be stateful and ready to scale horizontally. We’d also have to be able to direct users to the right server whenever they opened the editor page. No one should experience a split-brain feeling as their edits conflict with edits from someone else.
Major technology decisions
Our core technology decisions revolved around scalability, compatibility across our tech stack, and fallback flexibility.
Yjs and CRDT
Most products with real-time collaboration features choose one of two paths: Operational transformations or CRDT. Google Docs, for example, uses operational transformations. Features that use CRDT include Apple’s Notes App, JupyterLab, and Zed.
CRDT was a good choice for us thanks to Yjs, an off-the-shelf implementation of CRDT that allowed us to avoid some of the complexities of implementing CRDT ourselves. We had considered other options, but Yjs proved much faster and more stable than anything else we considered.
During the development process, we encountered minor issues in Yjs, and a few team members were able to contribute to the Yjs project. We use a customized version of y-websocket to relay messages between connected clients.
Node.js
Node.js needs no introduction. The primary reason we chose it is that Yjs is written in JavaScript. With node.js, we could rely on a common library compatible with both the front end and the server.
Now, we have five services for real-time collaboration and have organized our codebase so that our services can share code easily. We only have one repository for these five services, which makes it quick to develop new services and reuse code.
Socket.io
WebSocket, the most popular protocol for real-time client-server communication, was a straightforward addition to our stack.
We encountered challenges with maintaining user connections, however, because many companies block WebSocket through firewalls to mitigate security risks. To address this, we integrated Socket.IO, an open-source solution that provides a fallback mechanism using HTTP long polling.
With this setup, connections default to WebSocket when available but gracefully fall back to HTTP long polling if WebSocket is blocked. Maintaining a healthy connection to the server is essential to a positive user experience but is a nontrivial problem to solve.
We're very happy with the Socket.IO solution here and fully expect to utilize it more widely throughout the product in the future.
How it works today
Our real-time collaboration system comprises three components. At its core is a collaborative document that supports concurrent mutations from multiple users.
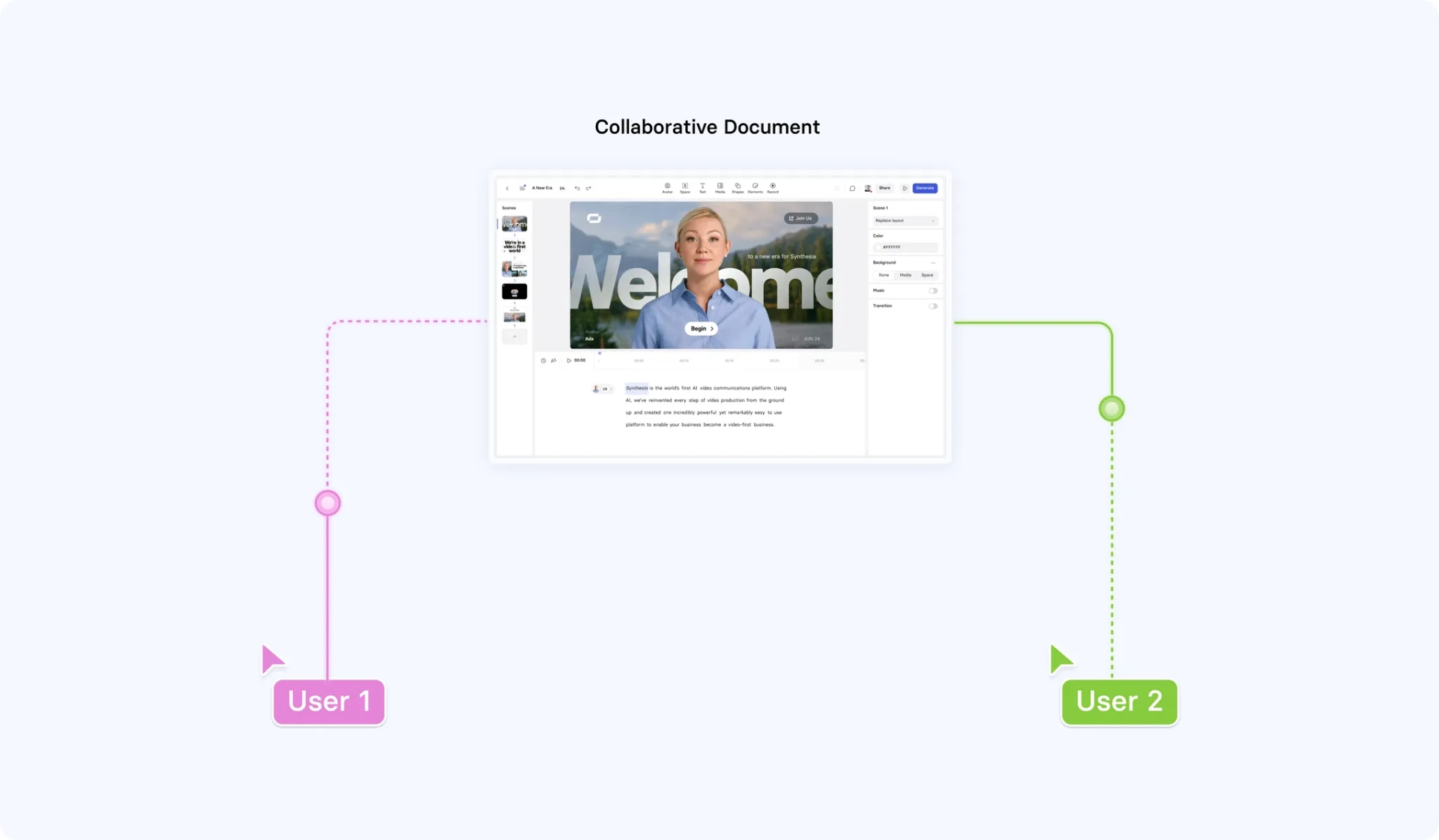
A mechanism for maintaining session affinity wraps around this so that users editing the same video connect to the same document.
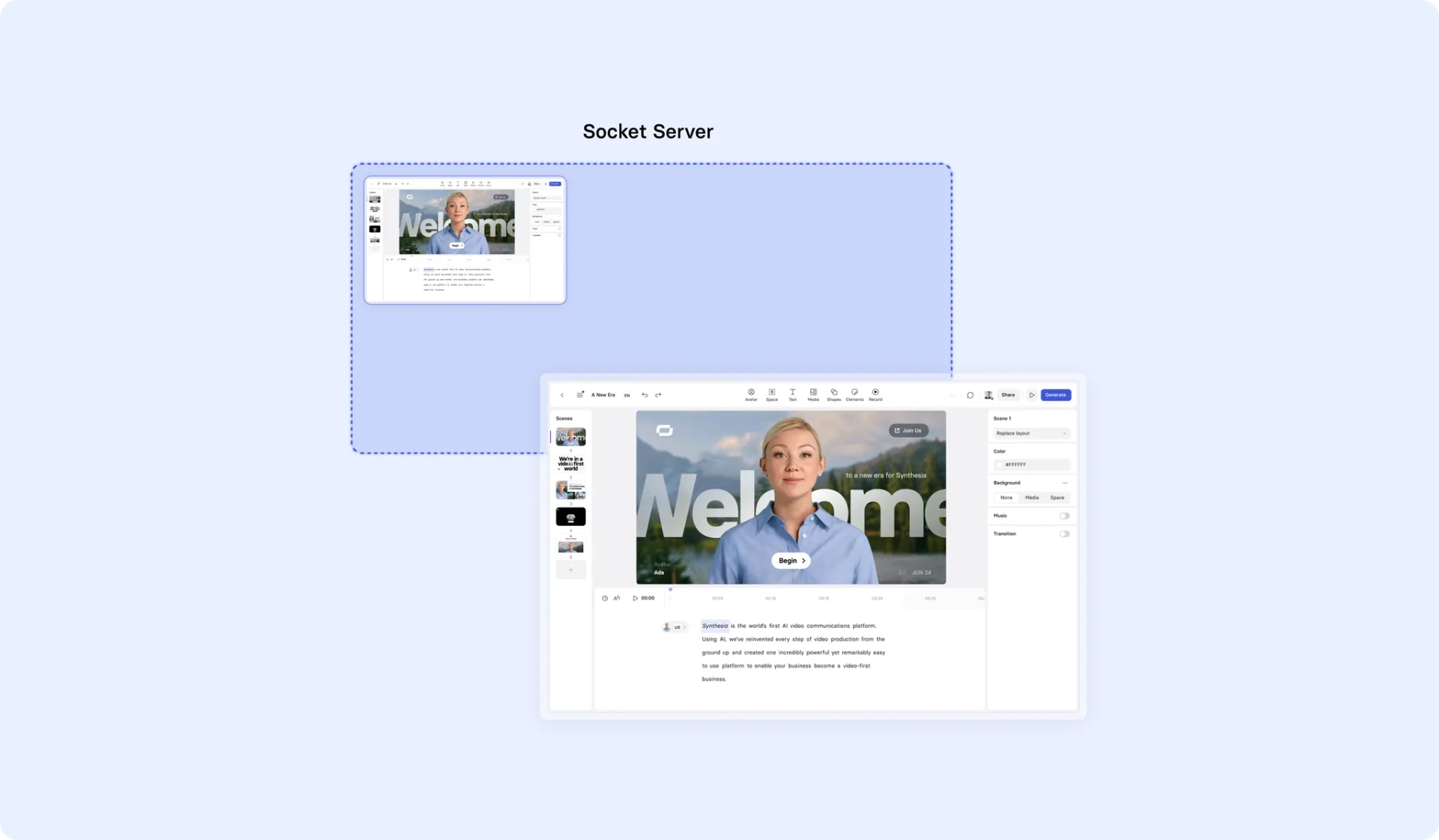
Finally, we have a load-balancing mechanism that ensures we can host many collaborative documents at any one time.
Collaborative document
The collaborative document is the data model at the heart of our real-time collaboration system.
Imagine a JSON representation of your video–it would describe what canvas elements you've included, the position of these elements in the scene, any animations you’ve applied, and so on. The collaborative document describes the same information but additionally resolves conflicting operations.
For example, if you and a friend were to separately add canvas elements, the document would resolve this so that both canvas elements are included in your video. We describe a "session” as an instance of a collaborative document with one or more users connected to it.
Session affinity
It’s likely obvious that, in a real-time collaboration system, users within a session need to connect to the same instance of the collaborative document. If we didn’t, users would run into what is known as a "split-brain" scenario, where there are two sources of truth for the current state of the video.
To this end, we host all sessions on a "socket server." These are inherently stateful, so we use a service registry mechanism to facilitate scaling up and down. When a socket server starts, it notifies the service registry that it’s available.
The service registry modifies the load balancer so that the newly started server can accept connections and then marks the socket server as ready. At this point, it’s an eligible candidate for new sessions.
When a session is created, we note it in the socket server record. For any other users attempting to edit the same video, the existing session is found, and they are connected to it.
Initially, we considered making the architecture stateless, but this would have required substantial design changes and could have introduced unforeseen issues. Ultimately, we chose a design that allowed us to better predict potential challenges.
Load balancing
During testing, we were surprised to learn that memory was the resource bottleneck for our socket servers rather than the number of client connections.
To mitigate this, we assign new sessions based on the number of loaded documents and the memory consumed rather than the number of client connections to the socket server. This helps distribute the load more evenly and prevents server freezes, which is especially important during deployments.
When we make a new deployment – to introduce a bug fix, new feature, or configuration change – all the servers need to be replaced because all current sessions have to be recreated.
Challenges along the way (and how we solved them)
We encountered several challenges along the way, some of which we predicted early on and some of which surprised us.
Plugging memory leaks
We noticed a memory leak, which seemed to be caused by the video documents that were loaded into the socket server. This memory leak was more noticeable than typical object memory leaks due to the size of documents in memory, which is around a few MB.
These memory leaks only occurred in the production environment, which made troubleshooting difficult. First, we implemented a graceful shutdown feature that terminates servers once they reach a certain memory threshold. Doing so helps us avoid abrupt server shutdowns caused by out-of-memory errors.
During each graceful shutdown, we generate server heap snapshots to analyze the root cause. The root cause analysis revealed that dangling documents were not being properly cleaned up. Yjs documents, in particular, were not being garbage collected even when there weren’t references to them at the application level.
We discovered this was happening because the documents were still being referenced by the Awareness object, which in turn was referenced by a setTimeout.
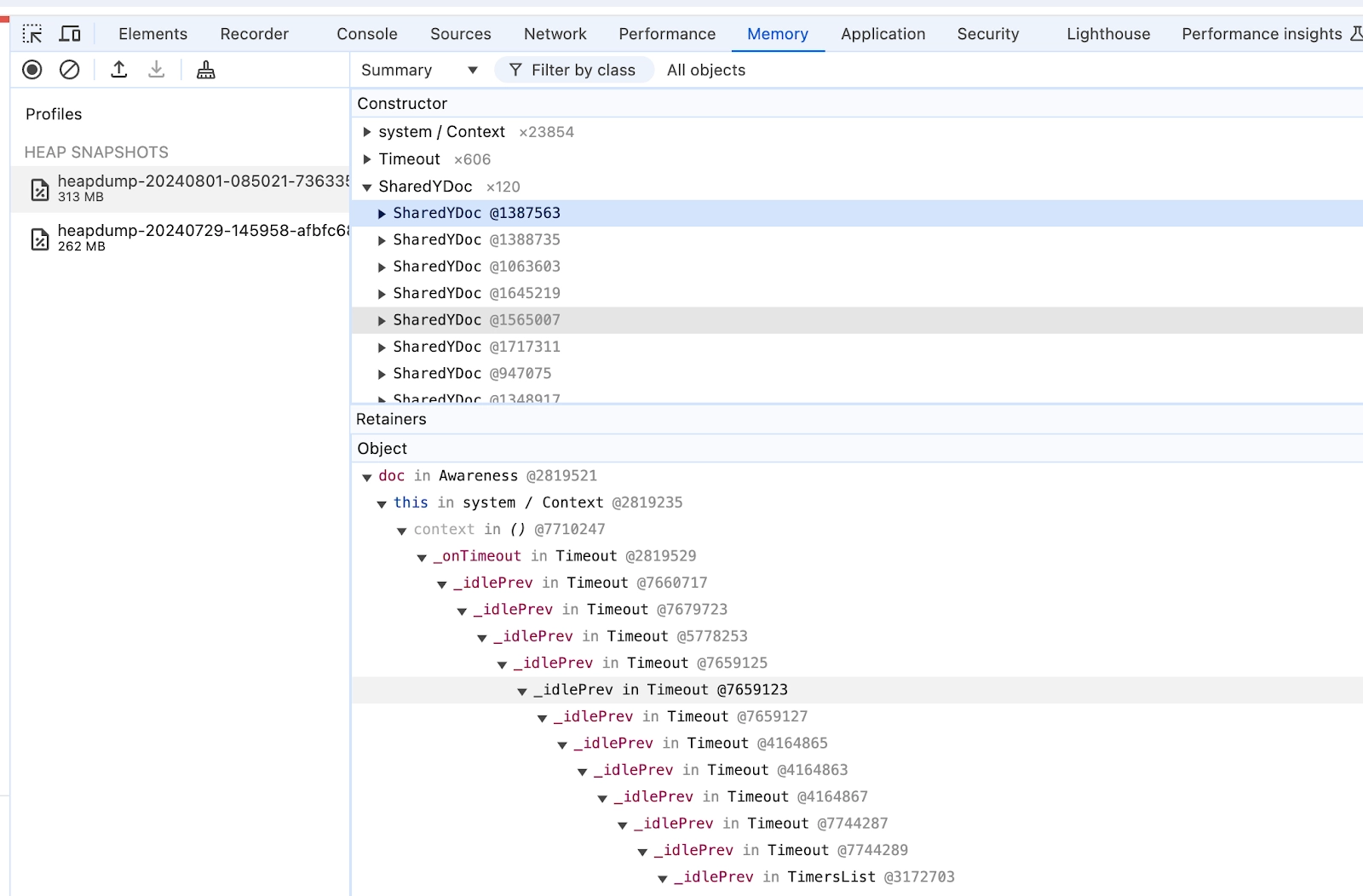
Note that generating a heap snapshot from a live instance is generally not a good idea because the instance will freeze while the snapshot is being created. That’s why we generated snapshots during the shutdown process after blocking incoming traffic.
Autoscaling without server strain
Autoscaling the socket servers is more challenging than traditional HTTP servers because:
- Due to the stateful nature and the sessions loaded in each server, scaling-in processes put pressure on the remaining servers during session reloads.
- It’s not possible to easily load test and measure the capacity of the servers with generic tools such as Locust, k6, or ApacheBench because we need a specific client implementation for generating load on the socket servers.
First, we configured the autoscaling policy based on memory and CPU usage because we knew memory usage would usually be the bottleneck due to in-memory documents.
One major source of server strain occurred when we’d scale in a socket server, terminate it, and transfer the sessions to the remaining servers. This transfer would be a significant strain, especially if the number of servers was running low or the number of sessions to transfer was high.
To address this, we identified:
- The optimal target memory size for the proper session count on each server.
- The appropriate minimum instance count for even load distribution.
When the balance was off, we encountered a domino effect: the failure of one instance triggered the sequential termination of other servers, leading to outages lasting several minutes.
We could conduct basic load tests using a custom tool, but that tool wasn’t sufficient for production-level testing. As a result, we set up target metrics for autoscaling based on historical metrics.
Database Migration
During our transition to the real-time collaboration architecture (RTC), we switched the database for video data from PostgreSQL to MongoDB.
Since we were storing video documents as JSON, MongoDB offered the flexibility and performance needed to accelerate our development process. As a result, however, we needed to migrate millions of video records from the old system to the RTC infrastructure, and we had to support both legacy and RTC video data in the system throughout the migration period.
To migrate all the video data, we developed a migration tool that runs on AWS Batch, and to ensure the continuous execution of the batch jobs, we made the process recursive. That way, it would spin up a new job at the end of a task based on specific conditions.
We also knew that the migration jobs would place a high load on our system. If we didn’t control the number of parallel tasks, the strain could be severe. Instead, we took a dynamic approach and ran more tasks during weekends or nights when user activity was low.
Due to these issues and a few others, including the transition from WebSocket to socket.io mentioned earlier, the complete migration took half a year. Despite these challenges, we completed the migration without any downtime.
Our rollout strategy
Once we completed development, we planned a staged rollout strategy to introduce the new feature to targeted users over time.
In November 2023, we started migrating select corporate clients to the new RTC infrastructure for beta testing. In parallel, we migrated the rest of our corporate clients but blocked access to the real-time collaboration feature via feature flag.
On February 29, 2024, we held a collaboration feature launch event, and in June, we published a launch post.
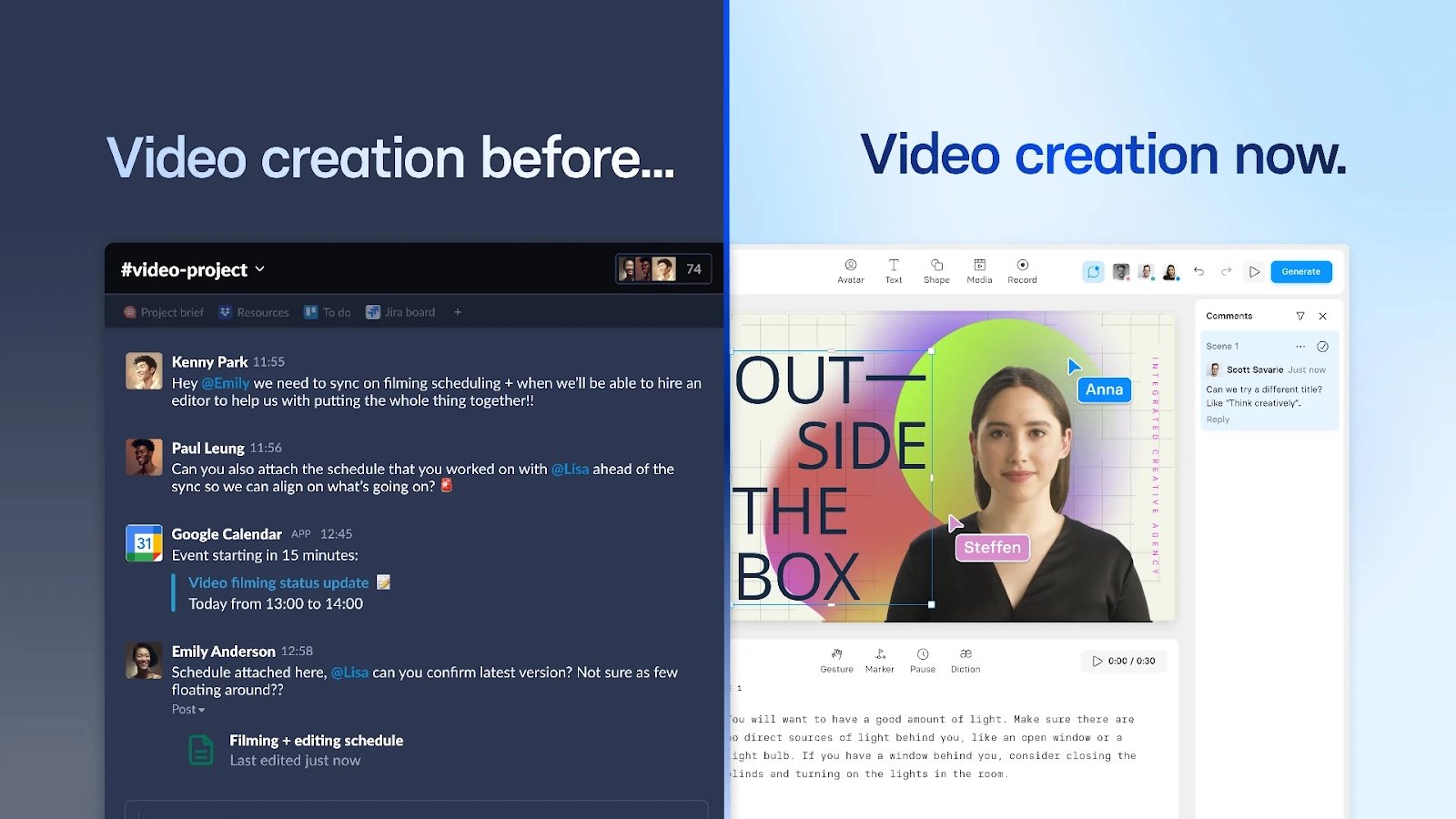
We finalized the migration of the remaining non-corporate users in May 2024. All in all, it took almost half a year to migrate all users to the new systems and nearly two years for the feature to be built, deployed, and proven.
Results so far and next steps
The results so far are promising. We recently measured a moment at peak usage time and learned that the number of active sessions has doubled since we launched the feature.
We’ve been growing exponentially, and our scalable architecture has enabled this growth. At the current growth rate, the next thing we need to make scalable would be the storage layer, which would pose an additional challenge.
To get qualitative feedback, we ran a Voice of the Customer report in Q2 of 2024. Customers told us they valued the fact that multiple users could collaborate on the same video project. They also told us, proving an early hypothesis, that allowing different team members to contribute their expertise and insights enhanced the overall quality of the final video.
Now, real-time collaboration will support every new feature. With spaces, avatars can speak from different environments; with expressive avatars, facial expressions look much more realistic and lifelike; and with our magic screen recorder, we can use AI to make screen recording much easier. But with real-time collaboration, the benefits of each feature extend to every person who wants to help make the video in question.
Now, numerous people can jump into a video, and every one of those users can see every new feature we develop.
About the author

Senior Backend Engineer
Sanghyun Lee
Sanghyun Lee is a Senior Backend Engineer at Synthesia, focusing on the development of the real-time collaboration feature in their AI video editor.




%201%20(1).jpg)
Frequently asked questions


